
第69届ISSCC(国际固态电路会议)以“Intelligent Silicon for a Sustainable World”为主题,于2022年2月20日至28日在线上举行。今年ISSCC从全球12个领域收到651篇,其中录用论文有200篇。本届会议上,中国大陆及港澳地区入围的论文共30篇,清华大学集成电路学院入围的论文数为6篇。快来一起学习这6篇论文吧!
High-Quality GHz-to-THz Frequency Generation and Radiation
A 53.6-to-60.2GHz Many-Core Fundamental Oscillator with Scalable Mesh Topology Achieving -136.0dBc/Hz Phase Noise at 10MHz Offset and 190.3dBc/Hz Peak FoM in 65nm CMOS
H.Jia, R. Ma, W. Deng, Z. Wang, B. Chi
Tsinghua University, Beijing, China
ML Processors
A 28nm 29.2TFLOPS/W BF16 and 36.5TOPS/W INT8 Reconfigurable Digital CIM Processor with Unified FP/INT Pipeline and Bitwise In-Memory Booth Multiplication for Cloud Deep Learning Acceleration
F. Tu1,2, Y. Wang1, Z. Wu1, L. Liang2, Y. Ding2, B. Kim2, L. Liu1, S. Wei1, Y. Xie2, S. Yin1
1Tsinghua University, Beijing, China
2University of California, Santa Barbara, CA
Power Amplifiers and Building Blocks
A 1V 32.1dBm 92-to-102GHz Power Amplifier with a Scalable 128-to-1 Power Combiner Achieving 15% Peak PAE in a 65nm Bulk CMOS Process
W. Zhu, J. Wang, R. Wang, J. Zhang, C. Li, S. Yin, Y. Wang
Tsinghua University, Beijing, China
ML Chips for Emerging Applications
A 28nm 27.5TOPS/W Approximate-Computing-Based Transformer Processor with Asymptotic Sparsity Speculating and Out-of-Order Computing
Y. Wang1, Y. Qin1, D. Deng1, J. Wei1, Y. Zhou1, Y. Fan1, T. Chen2, H. Sun1, L. Liu1, S. Wei1, S. Yin1
1Tsinghua University, Beijing, China
2Tsing Micro, Beijing, China
A 28nm 15.59μJ/Token Full-Digital Bitline-Transpose CIM-Based Sparse Transformer Accelerator with Pipeline/Parallel Reconfigurable Modes
F. Tu1,2, Z. Wu1, Y. Wang1, L. Liang2, L. Liu2, Y. Ding2, L. Liu1, S. Wei1, Y. Xie2, S. Yin1
1Tsinghua University, Beijing, China
2University of California, Santa Barbara, CA
Hardware Security
A 28nm 48KOPS 3.4μJ/Op Agile Crypto-Processor for Post-Quantum Cryptography on Multi-Mathematical Problems
Y. Zhu1, W. Zhu1, M. Zhu2, C. Li1, C. Deng1, C. Chen1, S. Yin1, S. Yin1, S. Wei1, L. Liu1
1Tsinghua University, Beijing, China
2Micro Innovation Integrated Circuit Design, Wuxi, China
High-Quality GHz-to-THz Frequency Generation and Radiation
毫米波多核基频振荡器
池保勇教授、贾海昆助理教授等发表题为“A 53.6-to-60.2GHz Many-Core Fundamental Oscillator with Scalable Mesh Topology Achieving -136.0dBc/Hz Phase Noise at 10MHz Offset and 190.3dBc/Hz Peak FoM in 65nm CMOS”的论文,将毫米波振荡器的相位噪声性能提升到了新的高度。5G毫米波通信大量采用高阶调制,对本振信号的纯度提出极高要求,现有CMOS工艺的振荡器难以满足本振纯度的要求,成为5G毫米波通信的瓶颈之一。研究团队提出了基于模式抑制的多核振荡器耦合机制,相比于常规电阻耦合更适用于毫米波频段;同时提出了网状多核拓扑架构,有效地减小了芯片面积和电源压降。采用65nm的CMOS工艺实现的16-核基频振荡器在1MHz频偏处的相位噪声为-111.7dBc/Hz,比文献中相似频段的现有最低水平降低了7.0dB。
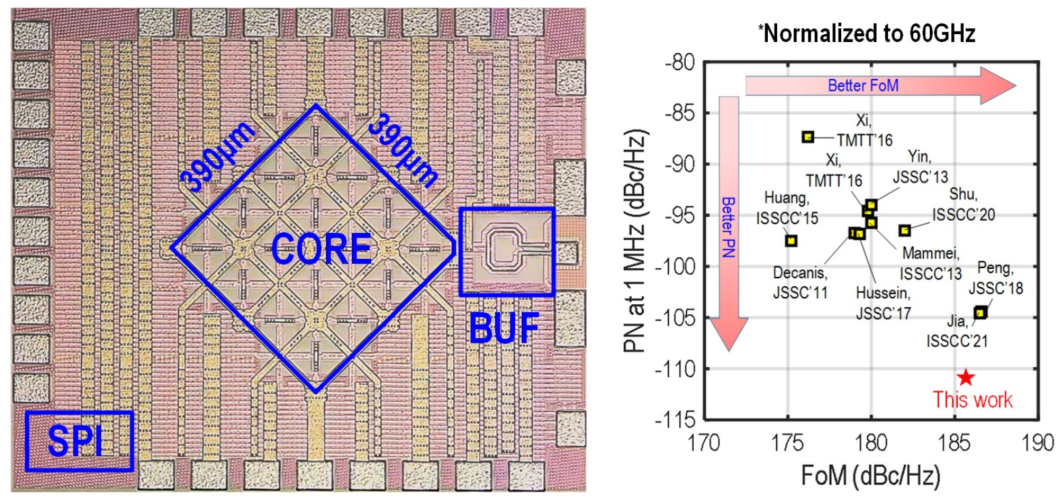
毫米波多核基频振荡器芯片照片及性能比较
ML Processors
AI芯片设计新范式,首款面向云端AI场景的可重构数字存内计算芯片ReDCIM
魏少军、尹首一教授等发表题为“A 28nm 29.2TFLOPS/W BF16 and 36.5TOPS/W INT8 Reconfigurable Digital CIM Processor with Unified FP/INT Pipeline and Bitwise In-Memory Booth Multiplication for Cloud Deep Learning Acceleration”的论文。存内计算架构可直接在存储器内完成计算,近年来被认为是一种能够突破冯诺依曼瓶颈的新型AI计算架构。然而,目前大多数存内计算AI芯片是基于模拟计算架构设计的,它们的模拟计算误差限制了计算精度,固定的存内计算架构限制了功能灵活性。这使得模拟存内计算架构只适合应用在对计算精度和灵活性要求不高的低功耗边缘端AI场景。随着高精度大规模AI模型不断涌现,在数据中心等云端AI场景进行训练和推理的算力需求日益增长。针对以上问题,研究团队提出AI芯片设计的新范式,将可重构计算与数字存内计算架构融合,兼顾能效、精度和灵活性,设计出国际上首款面向云端AI场景的可重构数字存内计算芯片ReDCIM。该芯片首次在存内计算架构上支持高精度浮点与整数计算,可满足云端AI推理和训练等各种任务需求。ReDCIM芯片在TSMC 28nm工艺上成功流片,可达到29.2TFLOPS/W的BF16浮点能效和36.5TOPS/W的INT8整数能效。

ReDCIM芯片及硬件指标
Power Amplifiers and Building Blocks
W波段硅基CMOS高功率功率表放大器芯片
王燕教授等发表了题为 “A 1V 32.1dBm 92-to-102GHz Power Amplifier with a Scalable 128-to-1 Power Combiner Achieving 15% Peak PAE in a 65nm Bulk CMOS Process”的论文。针对毫米波段硅基CMOS工艺输出功率受限的挑战展开研究,研究团队提出一种可扩展的混合式的基于中心馈入和外侧馈入耦合线的功率合成方法来克服毫米波功率放大器的功率合成方法来克服毫米波频段的输出功率和功率效率极限。原型PA采用65nm CMOS工艺实现,并集成了可扩展的128路合1的高效率功率合成网络。该128合1功率合成网络高效率地合成了16个8路合成子单元PA的共128路功率输出并在1V电源电压下,98GHz频点处朝外输出了32.1dBm的输出功率,峰值功率效率为15%。我们所提出的PA输出了比传统W频段CMOS PA高~10×的输出功率。
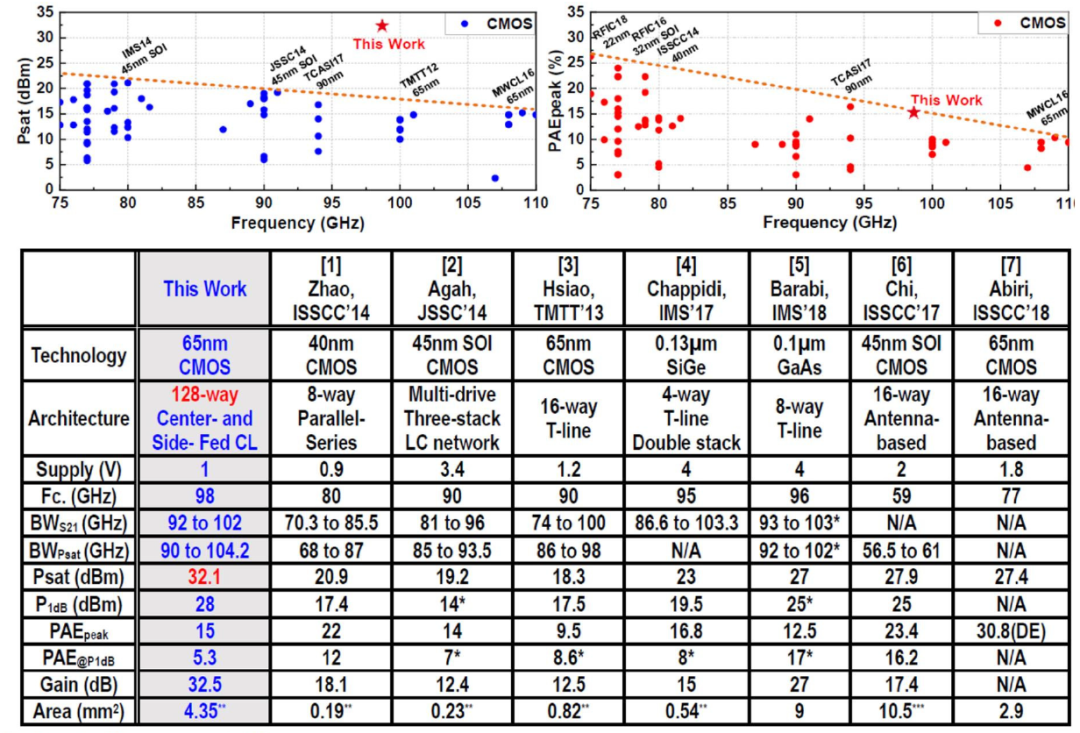
所提出的W频段PA相比传统工作的性能提升和比较
ML Chips for Emerging Applications
数字自注意力神经网络处理器
魏少军、尹首一教授等发表题为“A 28nm 27.5TOPS/W Approximate-Computing-Based Transformer Processor with Asymptotic Sparsity Speculating and Out-of-Order Computing”的论文。自注意神经网络Transformer是一种新兴的AI模型,在自然语言处理、计算机视觉等领域实现了突破性进展。然而,现有的应用于CNN的AI处理器,难以有效处理算力爆炸增长的自注意力模块,制约了Transformer的发展与应用。为实现Transformer模型的高效部署,研究团队设计并发布了国际首款全数字自注意力神经网络处理器。团队基于自注意力模块的偏微分特性,提出数值自适应的自门控计算单元,突破全局注意力的能耗瓶颈;同时,利用自注意力模块中的局部强关联性,提出高效预测机制,克服无效运算的能耗浪费问题;此外,根据自注意力模块的数据分布特性,提出乱序计算机制,打破固化计算顺序导致的资源利用率限制。所提出的自注意力神经网络处理器基于TSMC 28nm工艺成功流片,功耗仅为272.8mW, 峰值能效高达27.56TOPS/W。在高度智能化的Transformer模型GPT-2上,能耗仅为11.55μJ/Token,相比于英伟达最新发布的A100 GPU,可实现17.67倍的能效提升。
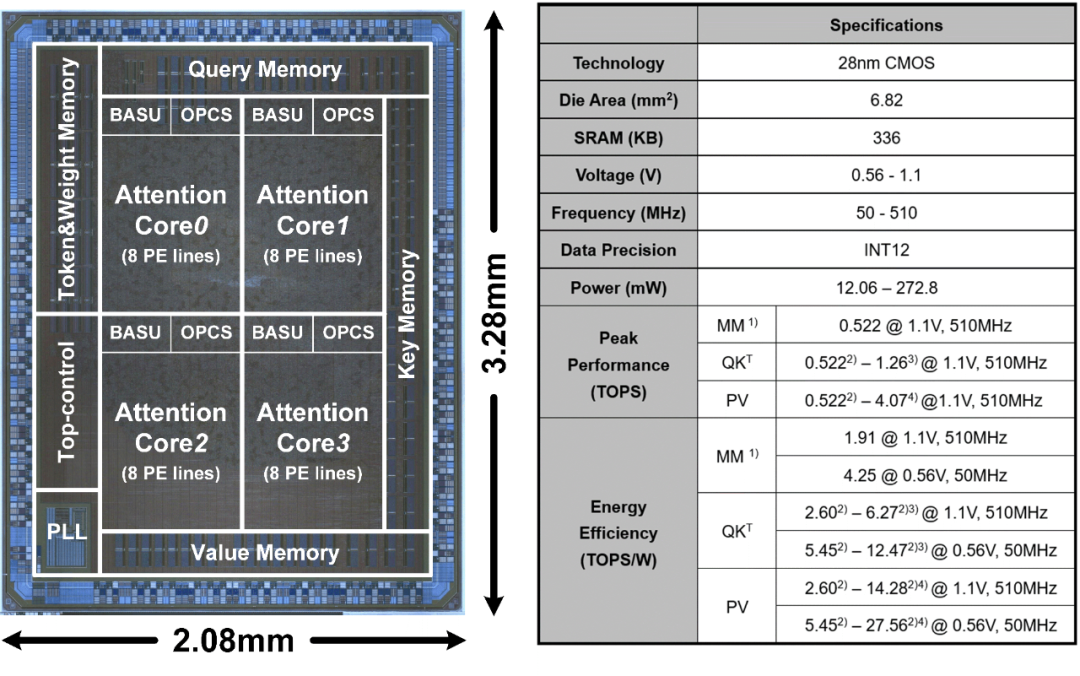
Transformer芯片及其硬件指标
存算融合自注意力神经网络处理器
魏少军、尹首一教授等发表题为“A 28nm15.59μJ/Token Full-Digital Bitline-Transpose CIM-Based Sparse Transformer Accelerator with Pipeline/Parallel Reconfigurable Modes”的论文。自注意力神经网络Transformer是当下最流行的AI模型之一,已广泛应用于自然语言处理、计算机视觉、生物信息等领域。其高精度、高访存、高算力需求给AI处理器设计带来巨大挑战。尽管模拟存内计算架构可以缓解冯诺依曼访存瓶颈问题,但模拟计算能支持数据精度有限,且传统的全并行架构在计算Transformer特有的自注意力模块时会产生大量片外访存。针对以上问题,研究团队沿用ReDCIM中将可重构与数字存内计算融合的新范式,设计出国际上首款存算融合自注意力神经网络处理器TranCIM。该芯片采用纯数字存内计算架构,无损实现高精度AI计算。TranCIM支持流水线和全并行的可重构计算模式:在计算自注意力模块时使用流水线模式消除片外访存,使中间数据直接在片上流入后级存内计算单元中;在计算传统矩阵乘时使用全并行模式保证最大计算吞吐。TranCIM芯片使用TSMC 28nm工艺成功流片,在典型Transformer模型BERT上仅产生15.59μJ/Token的能耗,相比于TSMC在ISSCC'21上推出的存内计算芯片可获得12.08倍的能效提升。
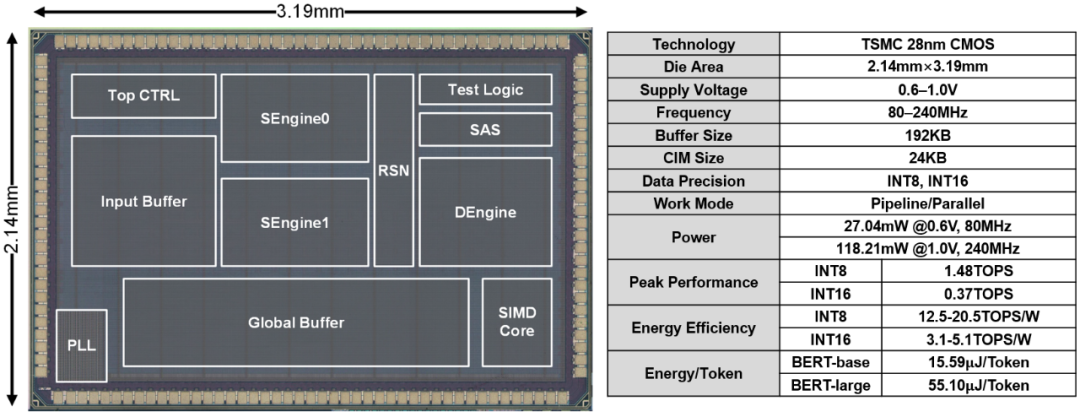
TranCIM芯片及硬件指标
Hardware Security
支持基于不同数学问题算法的后量子密码芯片
魏少军、刘雷波教授等发表题为“A 28nm 48 KOPS, 3.4μJ/Op Agile Crypto-Processor for Post-Quantum Cryptography on Multi-Mathematical Problems”的论文,针对即将标准化的后量子密码算法带来的计算存储开销大,算法类型多样且多变等问题,提出了一种混合计算阵列架构,配合调度、计算分离的设计策略和支持多种计算范式的计算单元,极大缓解了密码算法中各种算子造成的计算瓶颈;并完成了全球首款支持基于不同数学问题算法的后量子密码芯片研发,实验结果表明,与已有嵌入式后量子密码芯片比较,在支持更多算法的同时实现了2x的能耗提升和20x的速度提升。
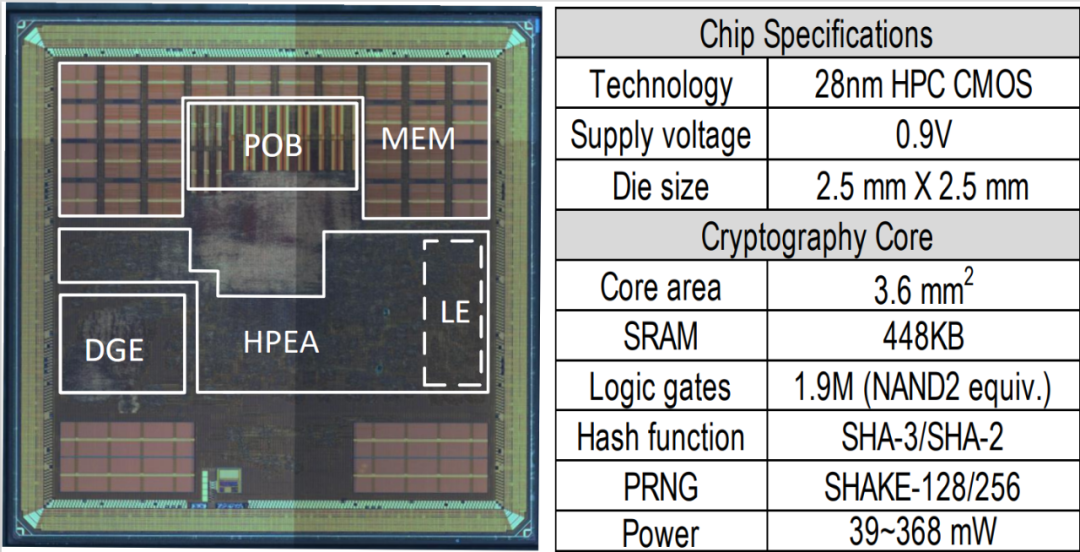
芯片管芯照片与特性
ISSCC 国际固态电路会议
ISSCC(International Solid-State Circuits Conference 国际固态电路会议)始于1953年,是集成电路设计领域最高级别的学术会议,素有“集成电路领域的奥林匹克”之称,通常是各个时期国际上最尖端固态电路技术最先发表之地。由于ISSCC在国际学术、产业界受到极大关注,每年吸引超过3000名来自世界各地工业界和学术界的参加者参会。
 清华主页
清华主页







